pandas 時系列データの扱いは日付のインデックス化が便利
この記事は2022年2月4日にリライトしました.
私はExcelとPythonの合せ技で家計簿を作っているのですが,データテーブルを操作するのにはpandasというライブラリを使っています.

 https://econ-blog.com/excel-kakeibo-python/
https://econ-blog.com/excel-kakeibo-python/Pythonを使ったことがある人なら分かると思いますが,pandasはデータ分析には必須のライブラリで,家計簿を作る時にも必須です.
この記事では,pandasのインデックスを日付に変更するメリットを備忘も兼ねてまとめました.
家計簿に日付データは必須なので,この機能をうまく使えばPythonでの家計データ管理が楽になります.
日付のインデックス化
たとえば,日付,費目カテゴリー,費目,金額,メモが用意されたデータベースを考えます.
おそらく,一般的な家計簿のフォーマットのベースになる形だと思います.
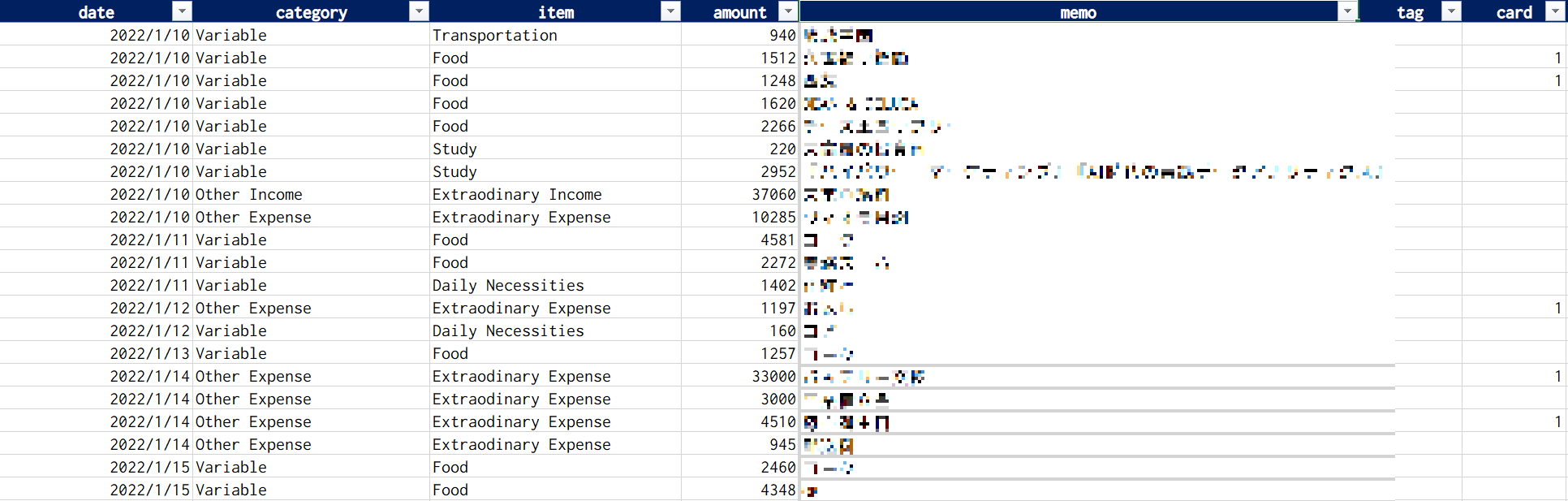
pandasではこれをデータフレームとして読み込んで色々な操作をしていきますが,この時に日付をインデックス化すると集計するときなどに後々便利です.
多分これだけだと分かりにくいと思うので実際にみていきます.
まず,日付をインデックス化せずにそのまま読み込むと下図のようになります.

一番左に0, 1, …と番号が振られていますが,これがインデックスで,Excelで言う行番号です.
0から始まっているのはPython(というかプログラミング言語全般)では1からではなく0からカウントするのが一般的なためです.
一方,日付をインデックス化して読み込むと下図のようになります.
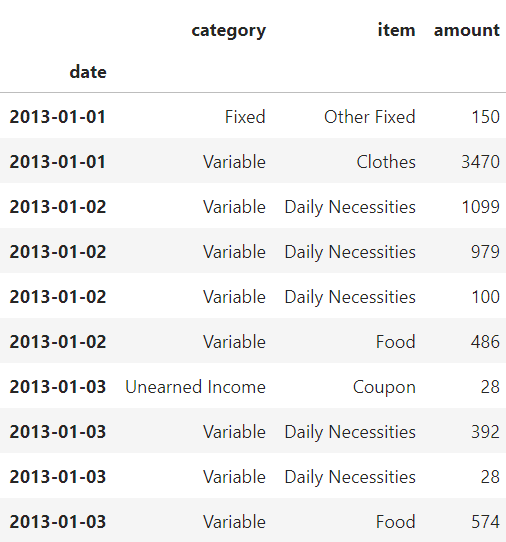
違いが分かりにくいのですが,さっきはあった0, 1, …という連番がなくなり,日付列が一番左にきてdateが一段下がっています.
日付インデックス化のメリット
見た目だけでは何がいいのかわからないのですが,日付をインデックス化しておくとPythonでコーディングをする時にとても楽になります.
たとえば,家計簿では月単位での合計を出す作業は必須ですが,そんな時にでも日付をインデックス化しておくとresampleメソッドが使えるようになり,一行のコーディングで各月の合計を出せます.
これが,日付をインデックス化していない場合はif文での条件分岐など,コードが長く複雑になります.
ExcelとPythonの使い分け
Pythonを知るまで,私はExcelのヘビーユーザーで,投資や家計管理は全てExcelでやってきました.
Excelはデータを手軽に入力できるというのが大きなメリットで,Pythonはコーディングすれば作業を自動化したり,Excel以上にきれいなグラフを描けるのが強みです.
なので,ExcelとPythonそれぞれ強みを活かすため,Excelにデータを入力し,それをPythonで加工すると使い分けています.
Pythonを使うようになった今でもExcelを使うことは多いですが,作業の自動化やグラフの描画はPythonで行うことがほとんどです.
家計簿に入力したデータを可視化して,そこから改善を見つけていくことが家計簿の肝ですが,Pythonを上手に使えば可視化の手間を減らすことができます.
それでは,また.