資産7,500万円は準富裕層のどこにいるのか?統計的に推定してみた
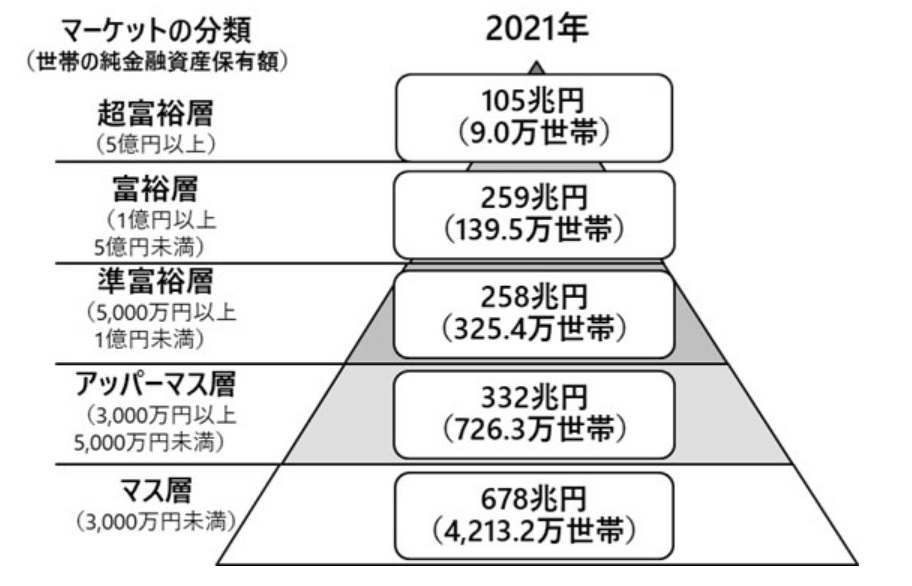
野村総合研究所の金融資産ピラミッドは,自分の資産規模は相対的にどれくらいなのかを知るための目安としてとても面白いですし,私も2年に一度の更新を楽しみにしていますが,欲を言えば,もっと掘り下げて自分がそれぞれのレイヤーの中でどこに位置するのかを知りたくなります.
例えば,私は準富裕層なのですが,このピラミッドからわかるのは平均が7,929万円/世帯(=258兆円 / 325万世帯)というだけで,これでけでは自分がどこらへんにいるのかのイメージは思い描きにくいです.
そこでこの記事では,準富裕層の分布を統計的に推定することで,自分が準富裕層の中でどこらへんに位置するのかをもう少し深堀りしてみました.
準富裕層の分布仮定:パレート分布
分布と言うとまずは正規分布が思い浮かびますが,正規分布を仮定すると両端の5,000万円と1億円にはほとんどいなくて,中心の7,500万円あたりに多く分布していることになりますが,これは資産分布としては不自然です.
資産5,000万円以上になると,資産額が大きくなるほどに難易度は上がるため,資産額が大きくなるほどに世帯数も少なくなっていくと考えるのが自然だと思うので,今回はパレート分布を想定しました.
パレート分布は所得分布をモデリングする時に多く用いられる確率分布で,グラフは右肩下がりとなり,今回の例で言うと5,000万円付近が最も多く,保有資産額が多くなるに従って世帯数が少なくなるという分布です.
統計値の推定とヒストグラム
分布を仮定したので,ここから代表的な基本統計量を推定していきます.
平均値は準富裕層の合計資産額と合計世帯数から7,929万円と計算できますが,他の統計値はわからないので統計的に推定する必要があります.
記事の趣旨から外れるので詳細の説明は省きますが,まず,パレート分布の形状を決めるβというパラメーターがあり,これは尺度(5,000万円)と平均(7,929万円)から求められるので,これによってパレート分布の形状がわかります(記事の最後にPythonコードを載せているので,興味のある方はそちらをどうぞ).
パレート分布の形状がわかれば基本統計量の推定が可能になり,ここでは平均値に加えて
- 第一四分位数(25%点)
- 中央値
- 第三四分位数(75%点)
を求めます.
これらがわかれば自分がどこにいるのかのイメージは結構はっきりしてきます.
Pythonで計算すると,以下のように求まります.
- 第一四分位数(25%点): 5,561万円
- 中央値: 6,460万円
- 第三四分位数(75%点): 8,344万円
平均値が7,929万円なので,中央値もここから大きく変わらないかと思いましたが,まさに「平均の罠」ですね.
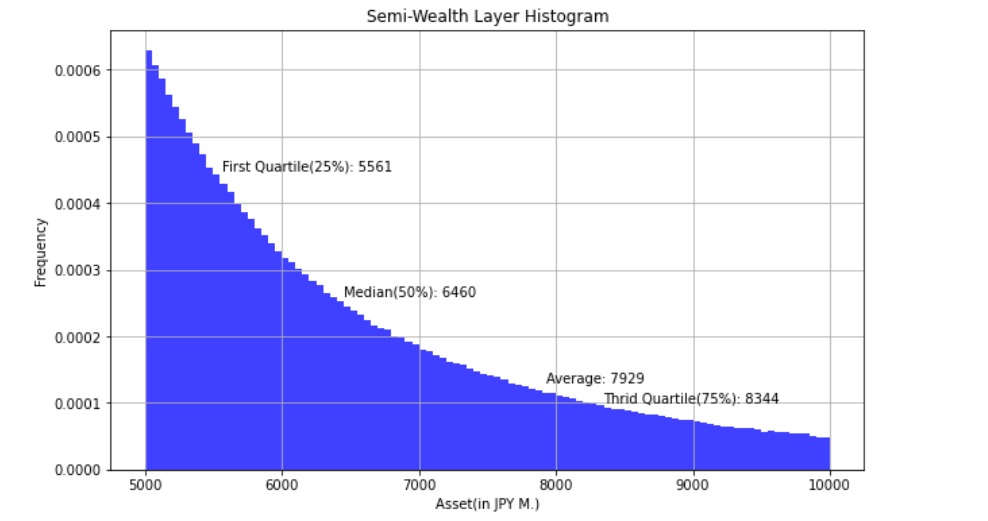
このモデルでは中央値は平均よりもずっと低い約6,500万円となり,第三四分位数が8,344万円なので,8,000万円であれば上位30%くらいには入っていそうです.
最後に,Pythonでのコードを載せておきます.
import numpy as np
import matplotlib.pyplot as plt
# Given parameters
sample_size = 3250000
xmin = 5000
xmax = 10000
average = 7929
# shape parameter beta
beta = (average / (average - xmin))
# Estimate first quartile Q1,median Q2,third quartile Q3
q1 = xmin*((1/0.75)**(1/beta))
q2 = xmin*((1/0.5)**(1/beta))
q3 = xmin*((1/0.25)**(1/beta))
# Generate the Pareto distributed data
pareto_data = (np.random.pareto(beta, sample_size) + 1) * xmin
# Filter data to be within the specified range
pareto_data = pareto_data[pareto_data <= xmax]
# Plotting the histogram
plt.figure(figsize=(10, 6))
plt.hist(pareto_data, bins=100, density=True, alpha=0.75, color='blue')
plt.title('Pareto Distribution Histogram')
plt.xlabel('Asset(in JPY M.)')
plt.ylabel('Frequency')
plt.text(5560, 0.00045, 'First Quartile(25%): 5561')
plt.text(6450, 0.00026, 'Median(50%): 6460')
plt.text(7929, 0.00013, 'Average: 7929')
plt.text(8344, 0.0001, 'Thrid Quartile(75%): 5561')
plt.grid(True)
plt.show()もし他のレイヤーでも同じような推定をしてほしい,というコメントがあればアッパーマス層や富裕層でもやってみようかなと思っています.
では,また.